MOFA-FLEX for MOFA users#
Introduction#
This tutorial follows the MOFA+ vignette on applying MOFA+ to the Chronic Lymphocytic Leukemia cohort and shows how to achieve equivalent results with MOFA-FLEX. The data consists of four modalities (views): DNA methylation, RNA-seq, somatic mutations, and drug response from a blood for 200 patients with Chronic Lymphocytic Leukemia (CLL).
Load libraries and data#
MOFA-FLEX integrates into the scverse ecosystem, the Python analogon to Bioconductor. It accepts AnnData and MuData containers as input, and many analysis and visualization steps can be achieved with scverse packages such as scanpy. For plotting, we use plotnine, a port of ggplot2 to Python. We additionally import the rdata package to be able to read the data, which is stored in an R workspace file.
import os.path
from tempfile import TemporaryDirectory
from urllib.request import urlretrieve
import anndata as ad
import mudata as md
import numpy as np
import pandas as pd
import mofaflex as mfl
import rdata
import scanpy as sc
from plotnine import *
Importing the dtw module. When using in academic works please cite:
T. Giorgino. Computing and Visualizing Dynamic Time Warping Alignments in R: The dtw Package.
J. Stat. Soft., doi:10.18637/jss.v031.i07.
theme_set(theme_bw())
md.set_options(display_style="html", display_html_expand=0);
import warnings
warnings.filterwarnings("ignore", category=FutureWarning)
We use data from the MOFAdata package, which contains the data matrices for the four modalities.
The features are in the rows and samples are in the columns.
with TemporaryDirectory() as tmpdir:
data_path = os.path.join(tmpdir, "cll.rda")
urlretrieve(
"https://github.com/bioFAM/MOFAdata/raw/refs/heads/master/data/CLL_data.RData",
data_path,
)
data = rdata.read_rda(data_path)
metadata = pd.read_table(
"https://ftp.ebi.ac.uk/pub/databases/mofa/cll_vignette/sample_metadata.txt"
)
AnnData is the scverse equivalent to Bioconductor’s SingleCellExperiment.
It can store one or multiple data matrices together with metadata for samples (called observations, .obs) and features (called variables, .var).
Contrary to the Bioconductor convention, samples are stored in rows and features in columns.
We create one AnnData object for each modality.
The individual modalities are then stored in a MuData object, which is the scverse equivalent to Bioconductor’s MultiAssayExperiment.
Because MuData takes care of aligning the different modalities with respect to missing samples and MOFA-FLEX is written with that in mind, we first remove samples where all features are missing.
We pass the metadata as an obs argument to the MuData constructor.
mdata = {}
for view_name, view_data in data["CLL_data"].items():
view_data = view_data[:, np.isnan(view_data).sum(axis=0) < view_data.shape[0]].T
mdata[view_name] = ad.AnnData(
X=view_data.values,
obs=pd.DataFrame(index=view_data.coords["dim_1"].to_index()),
var=pd.DataFrame(index=view_data.coords["dim_0"].to_index()),
)
mdata = md.MuData(mdata, obs=metadata.set_index("sample"))
mdata
Metadata.obs8 elements
| Gender | object | m,m,m,m,f,m,f,m,m,m,m,f,f,m,m,m,m,m,f,f,f,f,m,m,f,... |
| age | float64 | 90.73,85.47,83.47,47.90,73.26,54.85,64.36,69.72,58... |
| TTT | float64 | 0.02,1.57,3.07,0.82,1.40,1.51,0.90,0.92,1.30,2.03,... |
| TTD | float64 | 1.97,1.57,3.07,2.27,1.86,1.51,0.90,0.92,1.30,2.03,... |
| treatedAfter | object | True,False,False,True,True,False,False,False,False... |
| died | object | True,False,False,False,False,False,False,False,Fal... |
| IGHV | float64 | 0.00,0.00,1.00,0.00,0.00,1.00,0.00,1.00,1.00,nan,1... |
| trisomy12 | float64 | 0.00,1.00,0.00,0.00,0.00,1.00,0.00,1.00,0.00,0.00,... |
Embeddings & mappings.obsm4 elements
| Drugs | bool | numpy.ndarray | 1 columns |
| Methylation | bool | numpy.ndarray | 1 columns |
| mRNA | bool | numpy.ndarray | 1 columns |
| Mutations | bool | numpy.ndarray | 1 columns |
Distances.obsp0 elements
No distancesDrugs184 × 310
AnnData object 184 obs × 310 varLayers.layers0 elements
No layersMetadata.obs0 elements
No metadataEmbeddings.obsm0 elements
No embeddingsDistances.obsp0 elements
No distancesMiscellaneous.uns0 elements
No miscellaneousMethylation196 × 4248
AnnData object 196 obs × 4248 varLayers.layers0 elements
No layersMetadata.obs0 elements
No metadataEmbeddings.obsm0 elements
No embeddingsDistances.obsp0 elements
No distancesMiscellaneous.uns0 elements
No miscellaneousmRNA136 × 5000
AnnData object 136 obs × 5000 varLayers.layers0 elements
No layersMetadata.obs0 elements
No metadataEmbeddings.obsm0 elements
No embeddingsDistances.obsp0 elements
No distancesMiscellaneous.uns0 elements
No miscellaneousMutations200 × 69
AnnData object 200 obs × 69 varLayers.layers0 elements
No layersMetadata.obs0 elements
No metadataEmbeddings.obsm0 elements
No embeddingsDistances.obsp0 elements
No distancesMiscellaneous.uns0 elements
No miscellaneousTrain the model#
The model is automatically trained when a MOFAFLEX object is created. The MOFAFLEX constructor takes the data as its first argument and several objects containing the different settings as its following arguments in arbitrary order. For this tutorial, we will use 15 factors with a spike-and-slab prior and Gaussian likelihoods for all views. The spike-and-slab prior typically requires larger learning rates and longer training times than other priors, so we increase the learning rate to 0.01 and the early stopper patience to 500 epochs.
One major difference to the MOFA+ vignette is that it uses a Bernoulli likelhood for the Mutations modality, which is more appropriate for binary data.
However, MOFAFLEX yields different results compared to MOFA+ when using a Bernoulli likelihood.
This is probably due to the fact that MOFA+ uses a pseudo-Gaussian approximation for non-Gaussian likelihoods for reasons of computational tractability, while MOFAFLEX uses a more exact approach.
The pseudo-Gaussian approximation is likely also the reason that MOFA+ yields very similar results for Bernoulli and Gaussian likelihoods (try running the MOFA+ vignette with all Gaussian likelihoods).
model = mfl.MOFAFLEX(
mdata,
mfl.ModelOptions(n_factors=15, weight_prior="SnS", likelihoods="Normal"),
mfl.TrainingOptions(seed=42, save_path=False, lr=0.01, early_stopper_patience=500),
)
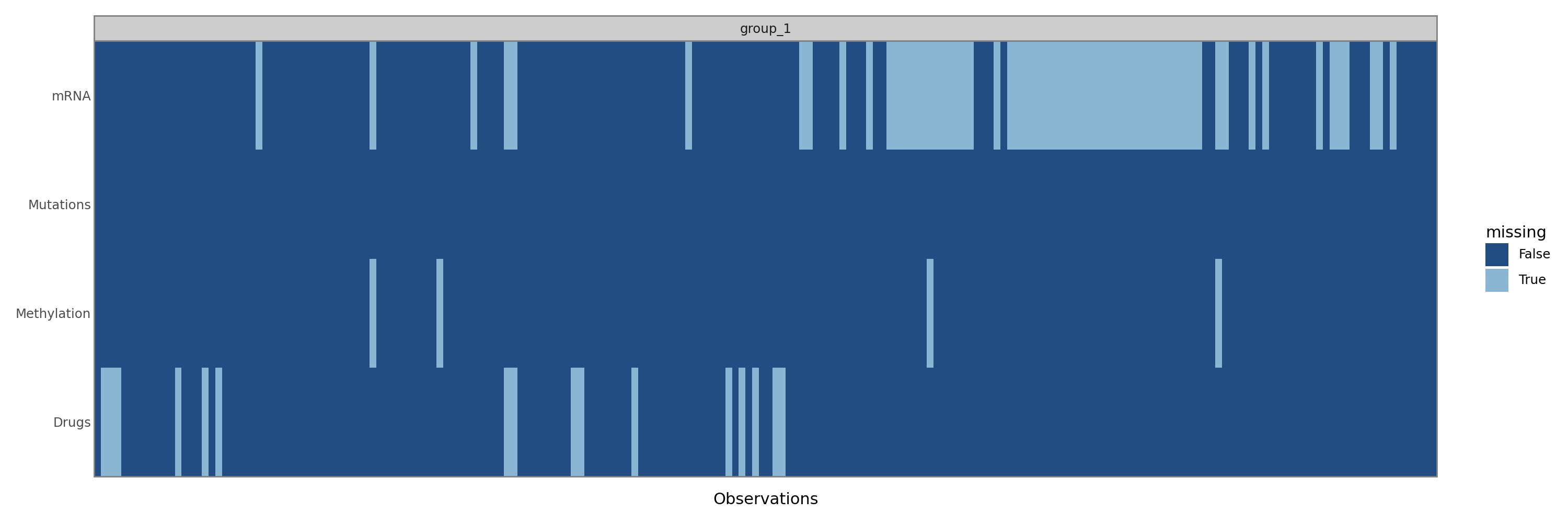
Basic quality control and overview of the trained model#
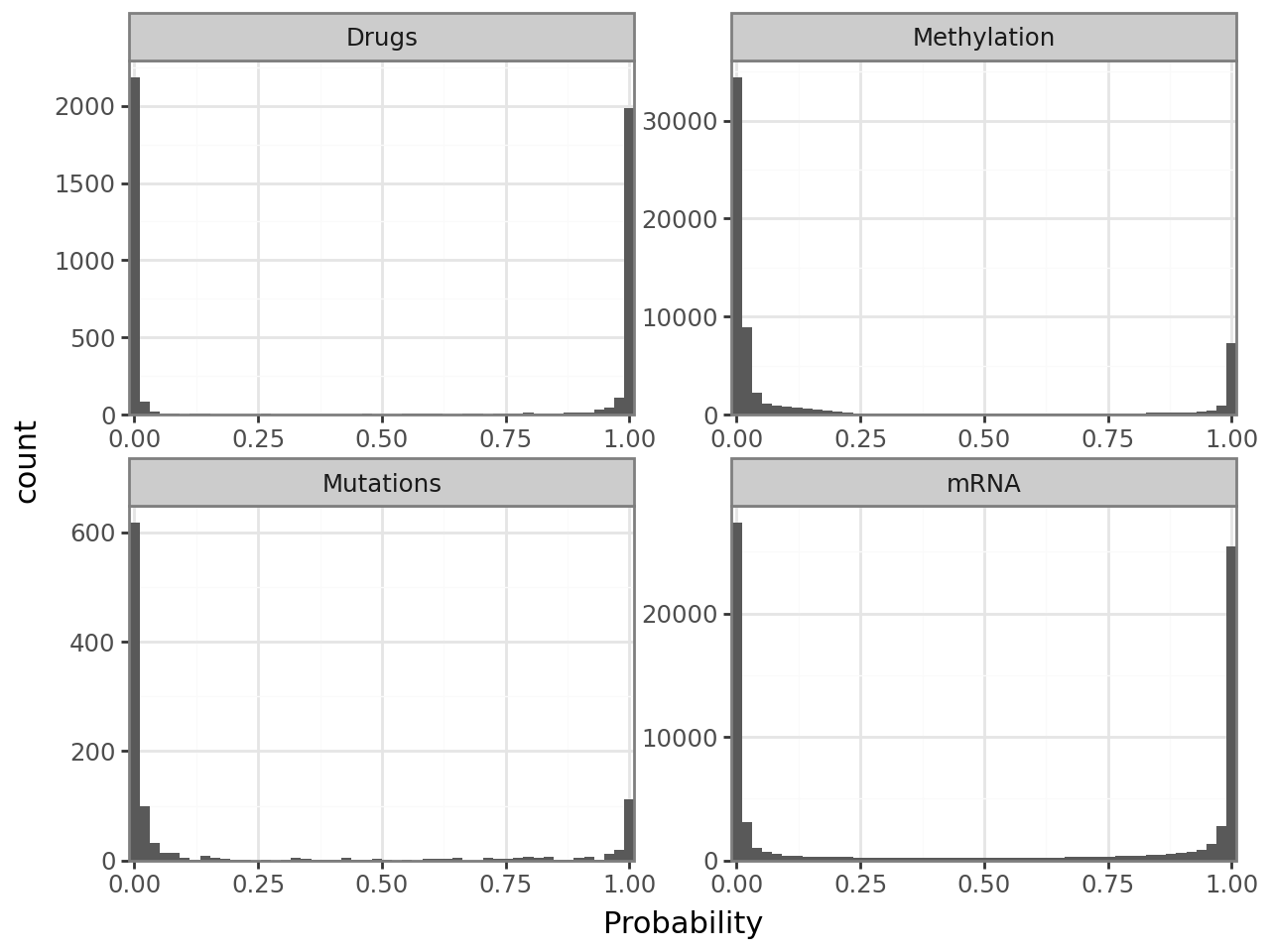
Posterior non-zero probabilities of the spike-and-slab prior#
An important quality control plot when using the spike-and-slab prior is the sparsity histogram, which visualizes the posterior probabilities that entries of the weight matrix are non-zero. Ideally, it has two peaks at 0 and 1, with very few counts at intermediate values. Should that not be the case, you probably need to increase the learning rate and/or the early stopper patience.
mfl.pl.weight_sparsity_histogram(model)
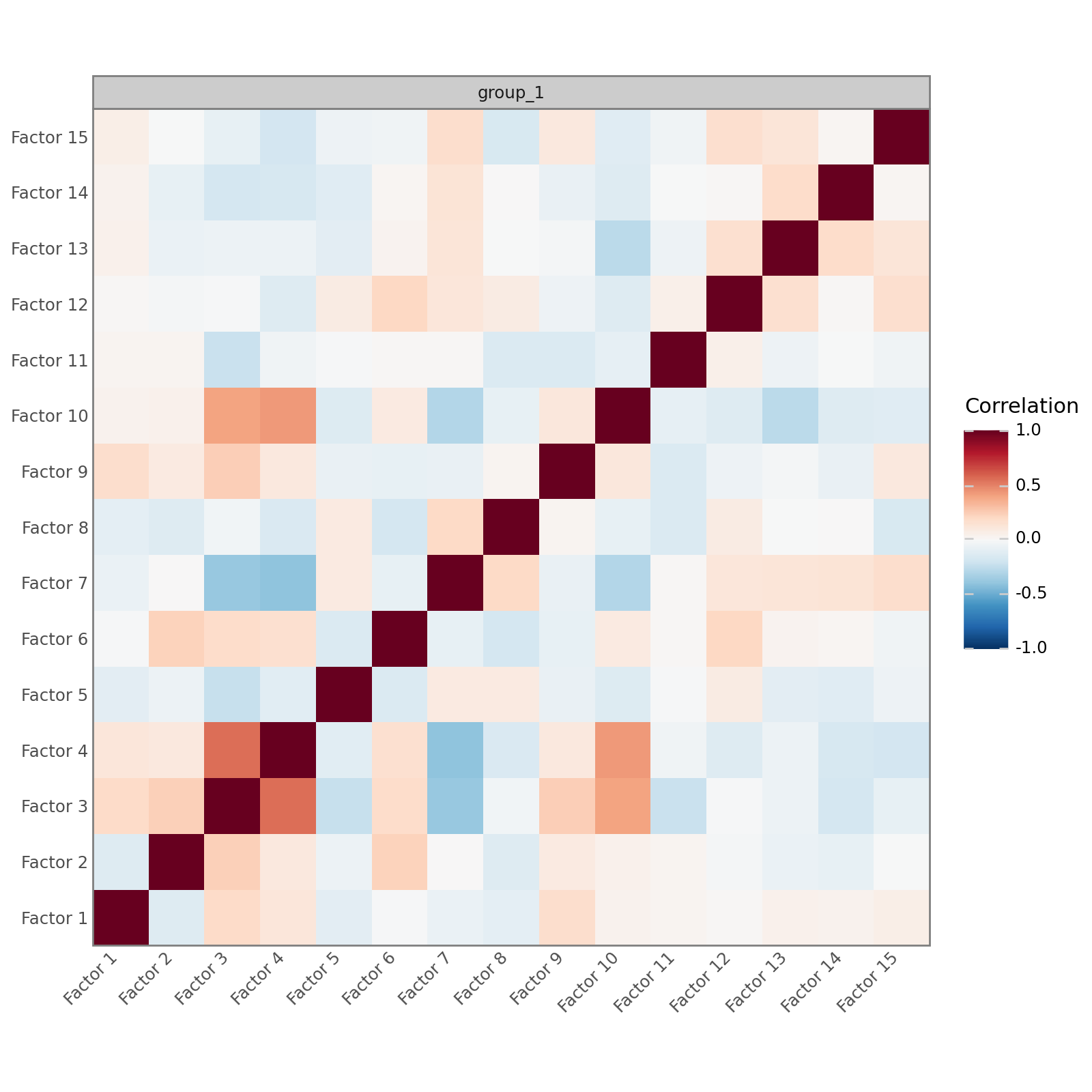
Correlation between factors#
In a well-specified model that is well-supported by the data, the factors should be mostly uncorrelated. MOFA-FLEX, like MOFA, does not impose any orthogonality constraints, but high correlations between many factors suggest a poorly specified model or a mismatch between the model and the data.
mfl.pl.factor_correlation(model)
Variance decomposition#
As in MOFA, the most important plot that MOFA-FLEX provides is the variance decomposition analysis, which shows the fraction of variance explained by each factor for all modalities. Note that this is most reliable for modalities with Gaussian likelihoods. Non-Gaussian likelihoods, especially the Bernoulli likelihood, may fail to to calculate the fraction of explained variance. For Bernoulli likelihoods, this is often the case if the data is heavily biased towards 0 or 1 and due to the fact that the predictions are not sufficiently close to 0 or 1, such that simply calculating the mean of the data yields a better prediction that the MOFA-FLEX model. If the fraction of explained variance cannot be calculated for a view, a warning will be printed immediately after training.
mfl.pl.variance_explained(model)
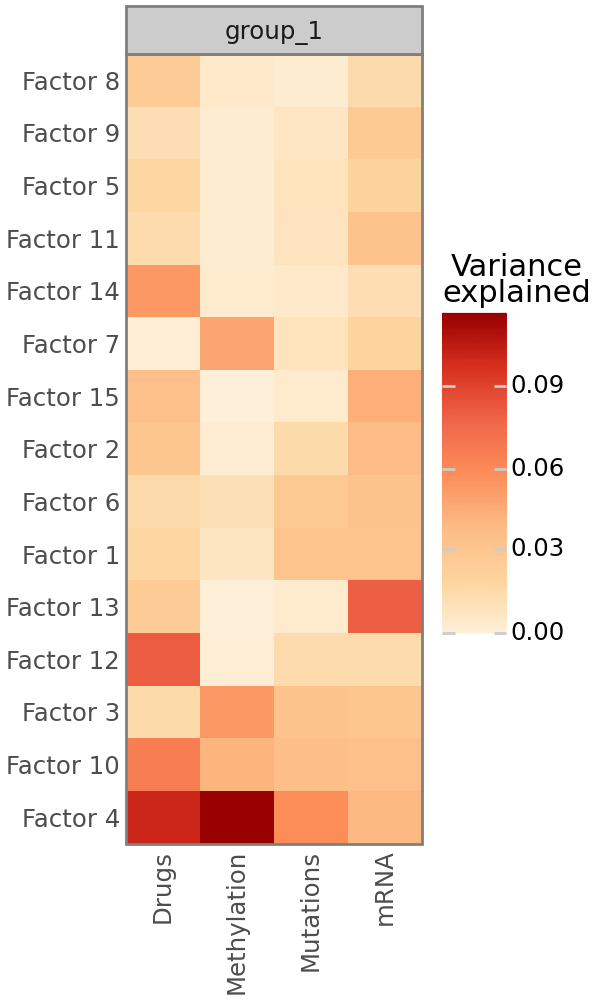
Characterization of Factor 4#
Plot factor values#
Similar to MOFA, MOFA-FLEX can plot factor values for each sample. Analogous to PCA, MOFA-FLEX factors can be viewed as a new coordinate system for the data. Since the data is centered prior to running MOFA-FLEX (for modalities with Gaussian likelihoods), each factor is also centered at zero. Samples with different signs manifest opposite phenotypes along the inferred axis of variation, with higher absolute value indicating a stronger effect.
mfl.pl.factor(model, factor=4)
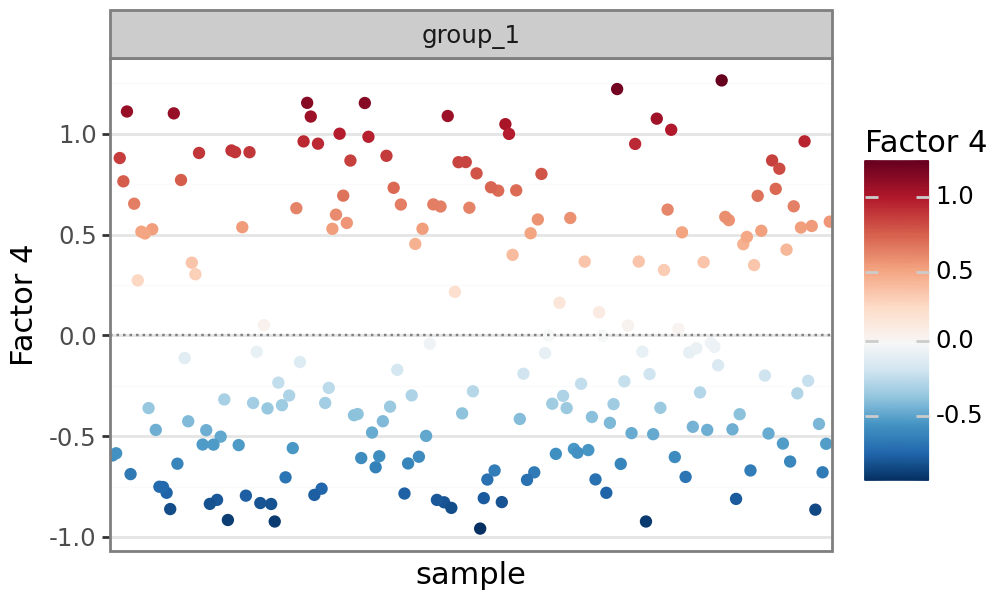
Plot feature weights#
The weights provide a score for each feature on each factor. Features with no association with the corresponding factor should have weights very close to zero, while features strongly associated with a factor should have large absolute weights. The sign of the weights indicates the direction of the effect: A positive weight indicates that the feature is positively correlated with the factor values, a negative weight indicates that the feature is negatively correlated with the factor.
Plot feature weights for somatic mutations#
By looking at the variance explained plot, we determined that factor 7 captures variation in all data modalities. Somatic mutations are very sparse, easy to interpret, and are likely to have downstream effects on other modalities. We therefore start with the Mutations modality.
We can plot the weights:
mfl.pl.weights(model, n_features=10, views="Mutations", factors=4, figsize=(5, 5))
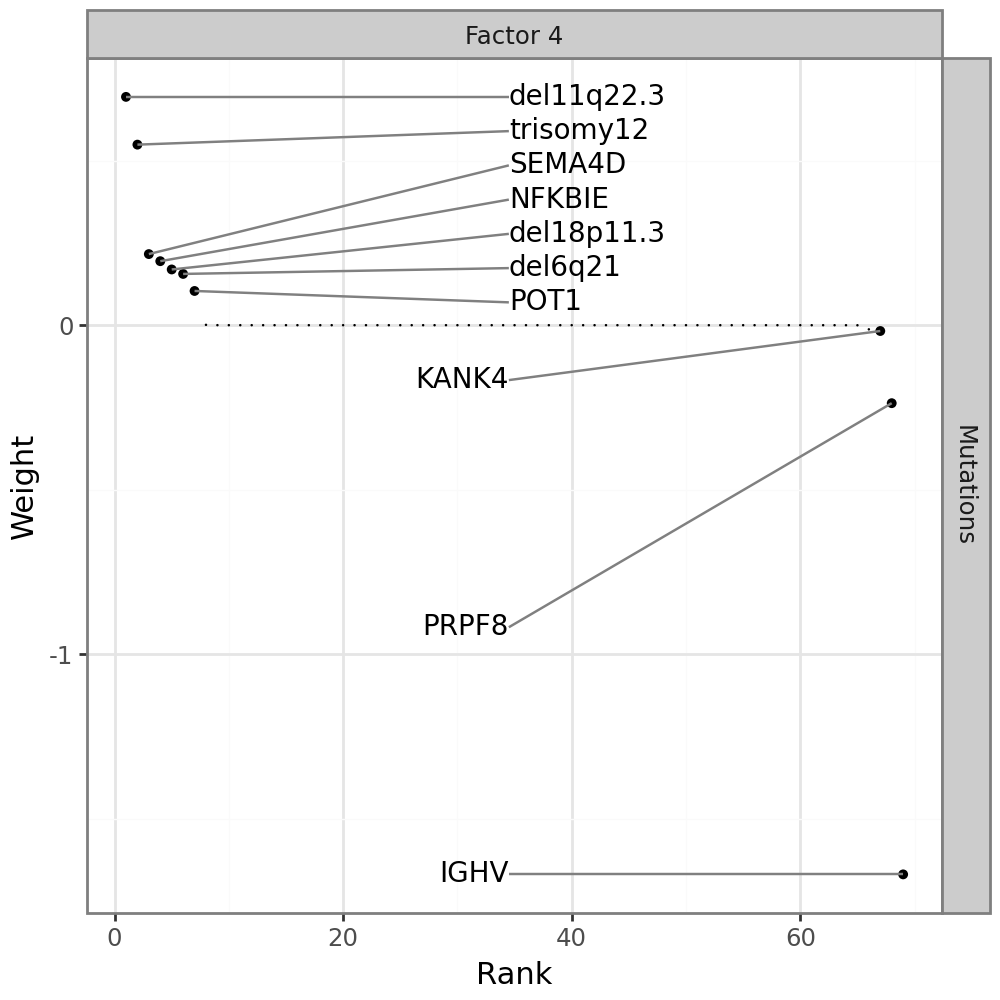
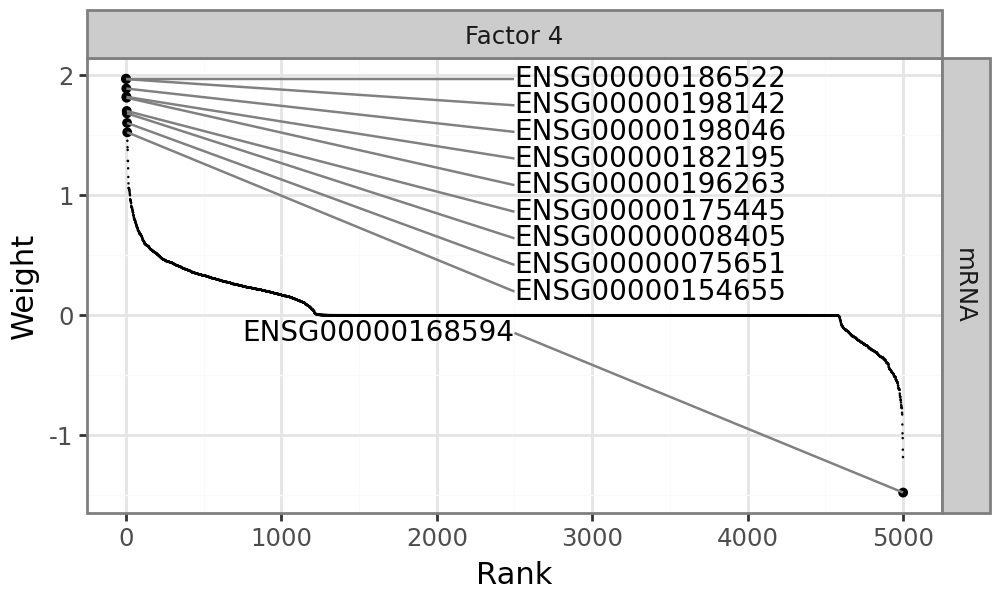
Most features are zero, indicating that they have no association with factor 7. One gene stands out: IGHV, the main clinical marker for CLL.
An alternative visualzation to the full weight distribution is a line plot displaying only the top features, annotated with the sign of the corresponding weight;
mfl.pl.top_weights(model, n_features=10, views="Mutations", factors=4)
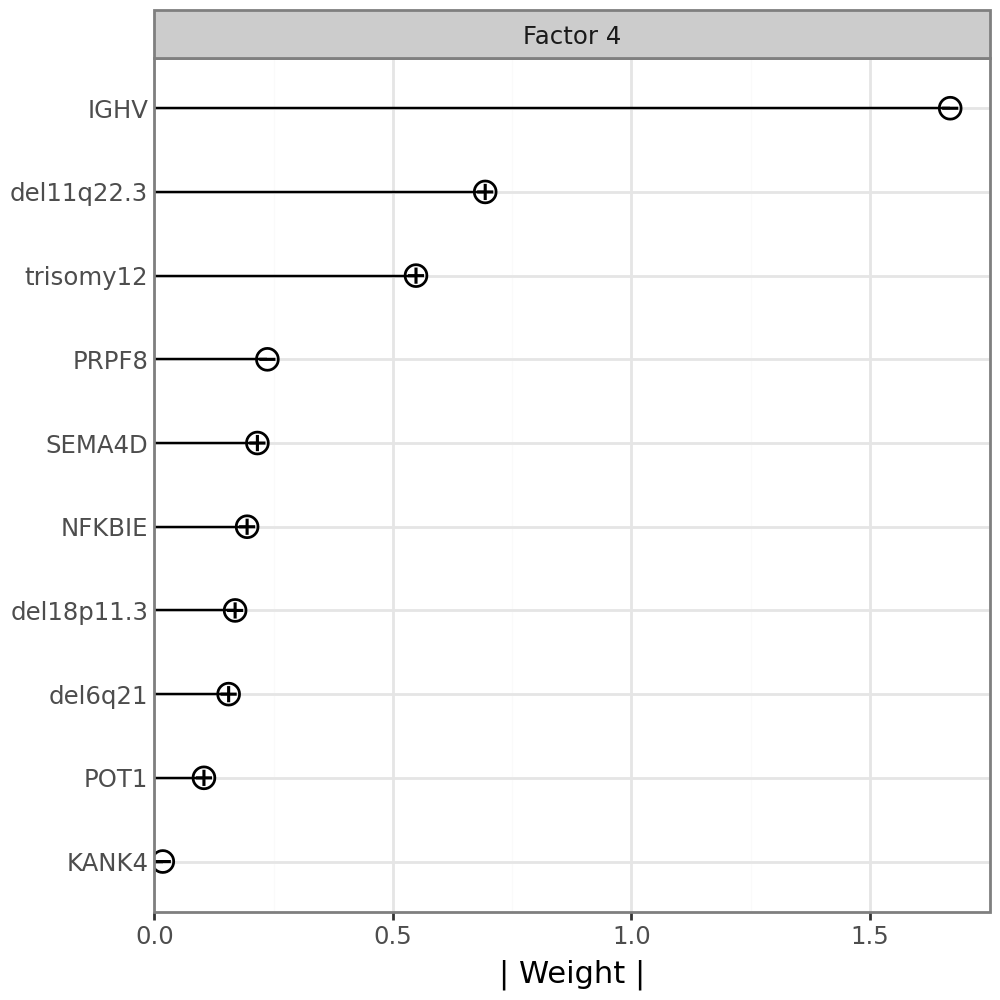
IGHV has a negative weight, indicating that samples with negative factor 4 values have an IGHV mutation, while samples with positive factor 4 values do not have an IGHV mutatoin. To confirm this, we can plot the factor values colored by the IGHV mutation status.
We use scanpy functionality to get a data frame with the IGHV mutation status in a column and the sample names as the index from the AnnData object we created earlier. We then add a new column containing values of factor 4 and plot.
(
ggplot(
sc.get.obs_df(mdata["Mutations"], keys="IGHV").assign(
factor4=model.get_factors()["group_1"]["Factor 4"],
IGHV=lambda x: x.IGHV.replace({1.0: "1", 0.0: "0", np.nan: "missing"}),
),
aes("IGHV", "factor4", color="IGHV", fill="IGHV", group="IGHV"),
)
+ geom_violin(alpha=0.3)
+ geom_sina()
)
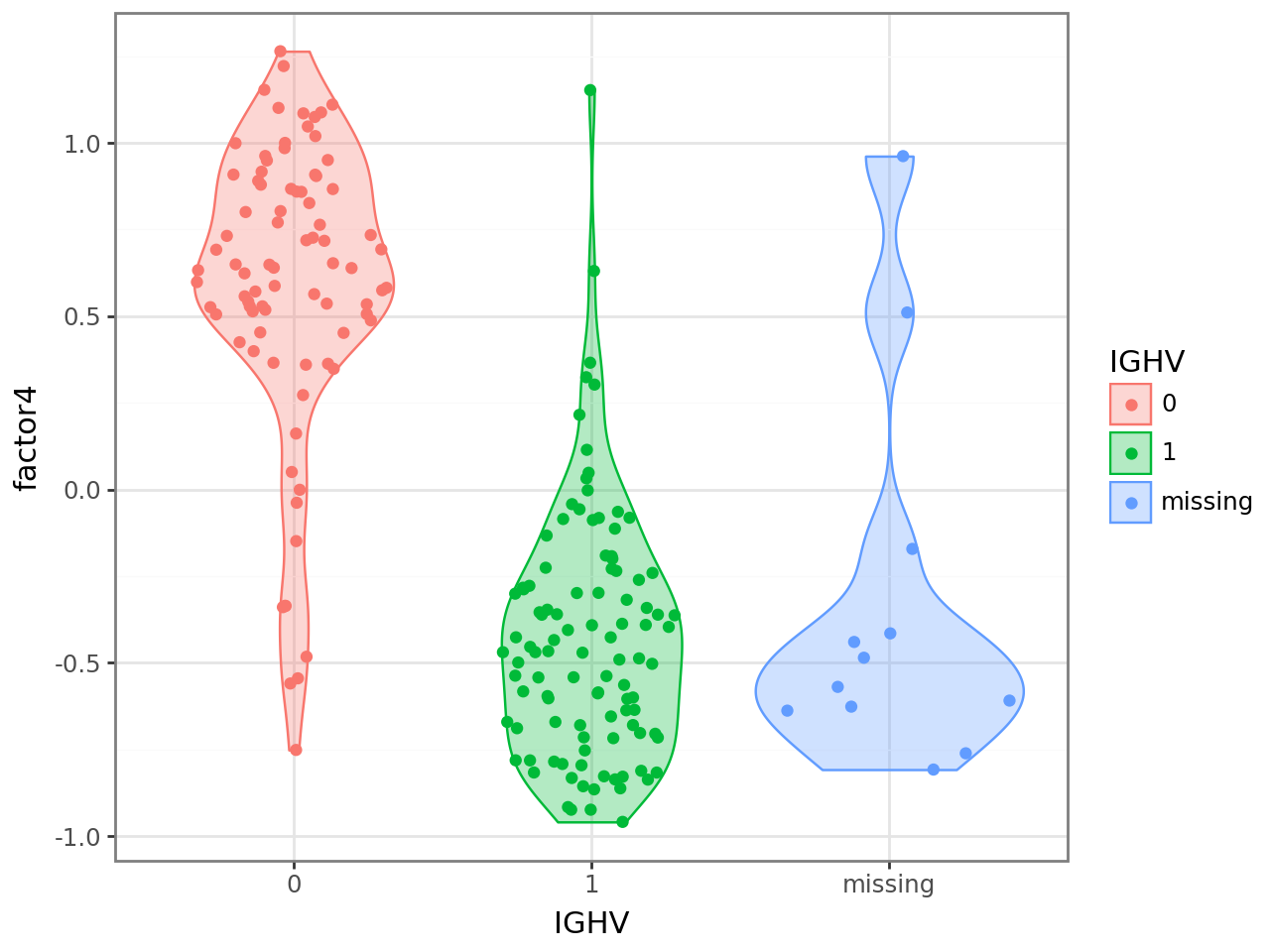
Similarly, we can use other covariates, which we can get directly from the .obs annotation of the MuData or AnnData objects.
(
ggplot(
mdata.obs[["Gender"]].assign(
factor4=model.get_factors()["group_1"]["Factor 4"]
),
aes("Gender", "factor4", color="Gender", fill="Gender"),
)
+ geom_violin(alpha=0.3)
+ geom_sina()
)
Plot gene weights for mRNA expression#
Since factor 4 drives variation across all data modalites, it makes sense to also visualize the mRNA expression changes that are associated with Factor 4:
mfl.pl.weights(model, n_features=10, views="mRNA", factors=4, figsize=(5, 3))
Plot molecular signatures in the input data#
In this case, there are many genes with large positive and negative weights. Genes with large positive weights should be more highly expressed in samples with an IGHV mutation, while genes with large negative values should be more highly expressed in samples without an IGHV mutation. We can verify this. Again, we use scanpy functionality to get a data frame with the expression values of the four genes with the highest (positive) weight and add a new column with factor 4 values. We then transform the data frame to a format suitable for ggplot and plot, coloring by IGHV mutation status.
f4_weights = model.get_weights()["mRNA"].loc["Factor 4"]
def plot_f4_expression(genes):
return (
ggplot(
sc.get.obs_df(mdata["mRNA"], keys=genes)
.assign(
factor4=model.get_factors()["group_1"]["Factor 4"],
IGHV=sc.get.obs_df(mdata["Mutations"], keys="IGHV").IGHV.replace(
{1.0: "1", 0.0: "0", np.nan: "missing"}
),
)
.melt(
id_vars=["IGHV", "factor4"], var_name="gene", value_name="expression"
),
aes("factor4", "expression"),
)
+ geom_point(aes(color="IGHV"))
+ geom_smooth(method="lm")
+ facet_wrap("gene")
)
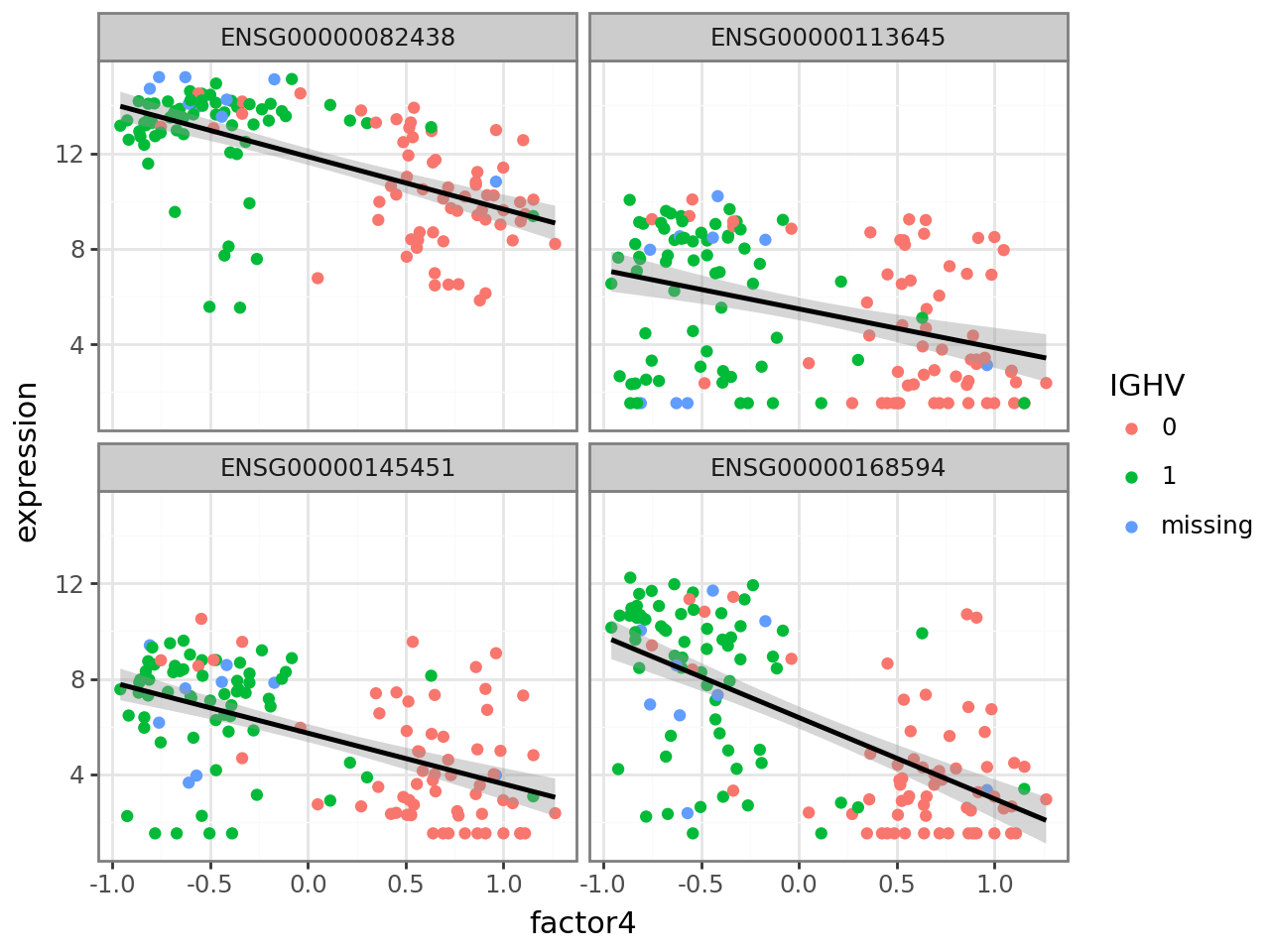
plot_f4_expression(f4_weights.nlargest(4).index.to_list())
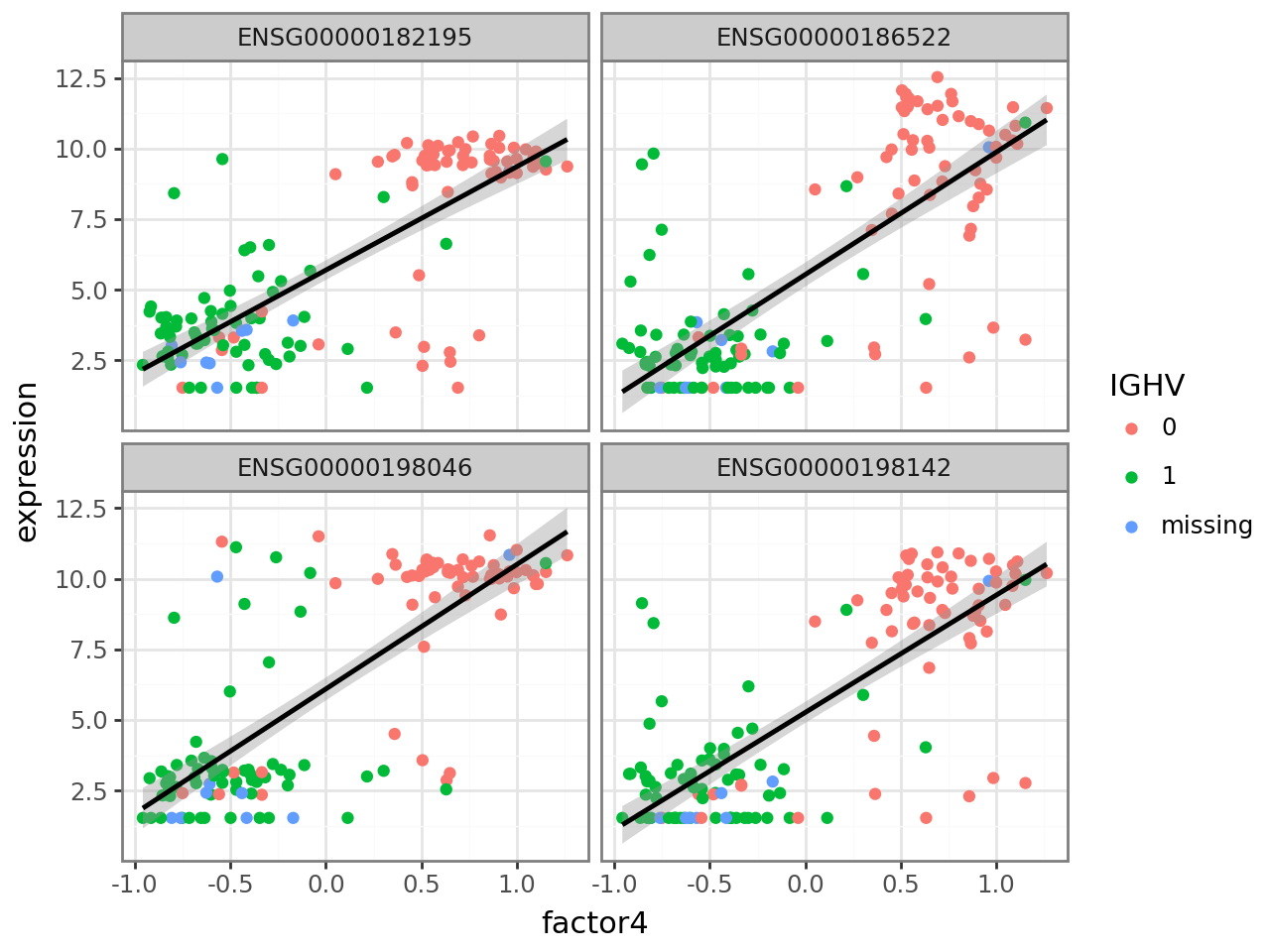
Similarly, we plot the four genes with smallest (negative) weight.
plot_f4_expression(f4_weights.nsmallest(4).index.to_list())
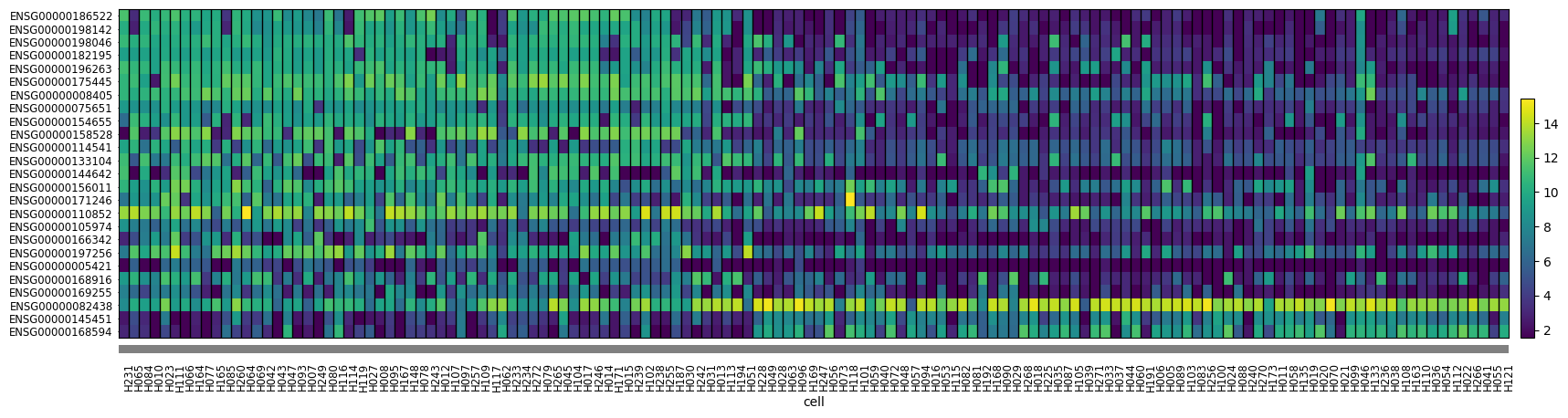
Alternatively, we can use a heatmap to plot gene expression for selected genes across all cells. Scanpy provides this functionality. The function takes an AnnData object and a list of genes to plot. We plot the 25 genes with highest absolute weight and order the samples by factor 4 value to be able to visually discern some patterns.
mdata["mRNA"].obs["cell"] = pd.Categorical(
mdata["mRNA"].obs.index,
categories=model.get_factors()["group_1"]["Factor 4"]
.sort_values(ascending=False)
.index.intersection(mdata["mRNA"].obs.index),
)
sc.pl.heatmap(
mdata["mRNA"],
f4_weights.to_frame()
.assign(absval=lambda x: x["Factor 4"].abs())
.nlargest(25, "absval")
.sort_values("Factor 4", ascending=False)
.index.to_list(),
"cell",
swap_axes=True,
dendrogram=False,
figsize=(20, 5),
)